🔍O jeito de buscar informação dentro da IA mudou completamente em 3 anos
Jerry Liu, criador do LlamaIndex (uma das ferramentas mais usadas para conectar IAs a bases de dados), fez um balanço de como a área evoluiu. Há três anos, ele ensinava técnicas avançadas de RAG, a sigla para o método que permite à IA consultar documentos antes de responder. Era tudo muito manual: você precisava ajustar como os textos eram cortados, indexados e recuperados. --- Hoje, segundo Jerry, a complexidade saiu das mãos do desenvolvedor e foi para o próprio agente de IA. Você dá ferramentas simples de busca para o agente e ele mesmo decide quais perguntas fazer para encontrar o que precisa. Outra mudança: antes o foco era hackear a janela de contexto (o limite de texto que a IA consegue processar de uma vez). Agora, o foco é decidir qual informação é realmente relevante para o problema. --- O resumo prático é que construir um assistente de IA que consulta seus documentos ficou mais simples por fora, porque a inteligência de busca migrou para dentro do modelo. Para quem usa, isso significa respostas melhores com menos configuração.
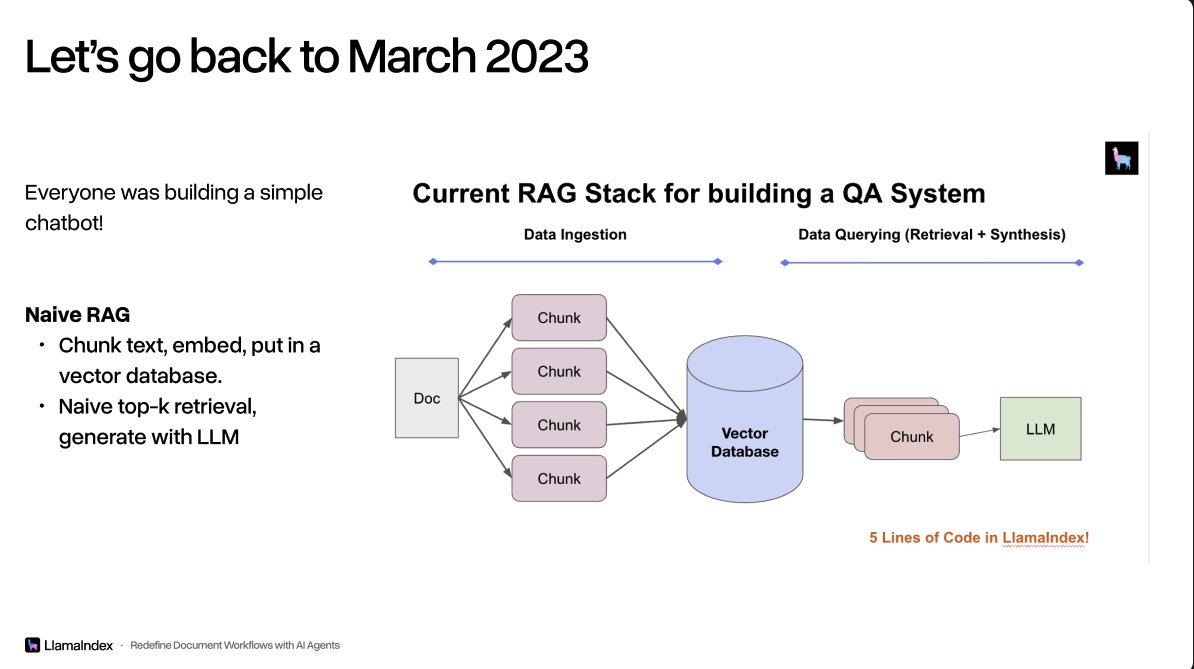
Jerry Liu, criador do LlamaIndex (uma das ferramentas mais usadas para conectar IAs a bases de dados), fez um balanço de como a área evoluiu. Há três anos, ele ensinava técnicas avançadas de RAG, a sigla para o método que permite à IA consultar documentos antes de responder. Era tudo muito manual: você precisava ajustar como os textos eram cortados, indexados e recuperados.
— @jerryjliu0 View on X
A busca por informações dentro de modelos de IA deixou de ser um processo técnico manual para tornar-se uma capacidade autônoma dos agentes. Em três anos, a arquitetura passou de configurações complexas de RAG (Retrieval-Augmented Generation) para sistemas onde o próprio modelo decide como, onde e o que perguntar para recuperar dados relevantes.
O fim do RAG artesanal
Há três anos, implementar capacidades de busca em aplicações de IA exigia expertise profundo em estratégias de chunking, modelos de embedding e fine-tuning de parâmetros de recuperação. Desenvolvedores precisavam:
- Segmentar documentos manualmente com tamanhos específicos de chunks
- Ajustar algoritmos de similaridade para indexação vetorial
- Otimizar pipelines de preprocessing para "hackear" a context window
O trabalho era essencialmente de engenharia de infraestrutura: forçar o modelo a processar mais texto do que suportava nativamente através de técnicas avançadas de fragmentação e recomposição de contexto.
Agentes como arquitetos da busca
Hoje, segundo Jerry Liu, criador do LlamaIndex, a complexidade migrou da infraestrutura para a cognição do agente. Em vez de pipelines rígidos e pré-configurados, desenvolvedores entregam ferramentas de busca simples ao agente, que formula suas próprias queries, decide quais fontes consultar e navega autonomamente entre bases de dados.
O desafio técnico deslocou-se de "como encaixar o máximo de dados possível na janela de contexto" para "como identificar informação realmente relevante para o problema específico". O intelligence retrieval migrou do middleware para dentro do próprio modelo.
O que muda para builders brasileiros
Para desenvolvedores e equipes de produto no Brasil, essa evolução representa uma redução significativa de boilerplate e complexidade operacional. S