💸Ramp levanta US$ 750 milhões e expõe o maior problema das empresas com IA
A Ramp, fintech americana de gestão de gastos corporativos, levantou uma rodada de US$ 750 milhões com avaliação de US$ 44 bilhões. Mas o mais interessante não foi o cheque: foi o alerta do CEO Eric Glyman sobre como as empresas estão queimando dinheiro com inteligência artificial sem ter a menor ideia do que está funcionando. --- Glyman deu um exemplo prático: a maioria das empresas usa os modelos mais caros e poderosos (os chamados 'de fronteira') para qualquer tarefa, inclusive para resumir reuniões ou atualizar calendários, coisas que modelos mais baratos resolvem perfeitamente. Redirecionar apenas 10% de uma fatura de US$ 10 milhões em IA para modelos mais simples economizaria quase US$ 1 milhão. --- O ponto central é que a IA está se tornando o terceiro grande pilar de custo das empresas, junto com pessoas e software. Mas, diferente de salários e licenças, quase ninguém sabe medir se aquele gasto em IA realmente gerou resultado. O financeiro quer cortar, a engenharia quer dobrar, e ninguém tem dados para resolver a briga.
A Ramp, fintech americana de gestão de gastos corporativos, levantou uma rodada de US$ 750 milhões com avaliação de US$ 44 bilhões. Mas o mais interessante não foi o cheque: foi o alerta do CEO Eric Glyman sobre como as empresas estão queimando dinheiro com inteligência artificial sem ter a menor ideia do que está funcionando.
— @eglyman View on X
O alerta que toda empresa brasileira deveria ouvir
A fintech americana Ramp levantou US$ 750 milhões com avaliação de US$ 44 bilhões, mas o mais relevante da rodada não foi o cheque. Foi o aviso do CEO Eric Glyman: empresas estão gastando milhões em inteligência artificial sem qualquer métrica para saber se o investimento vale a pena.
O tamanho do problema
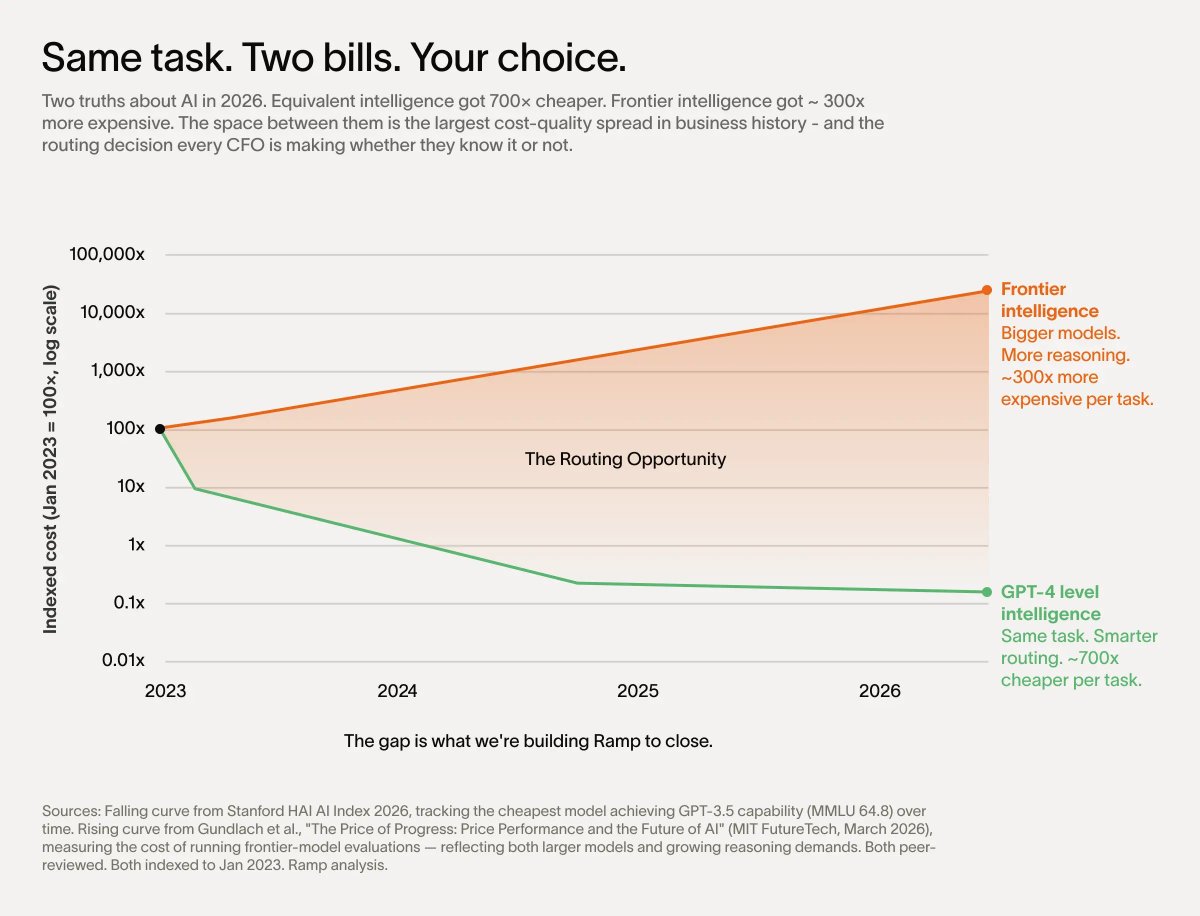
Glyman pointed out que a IA se tornou o terceiro maior pilar de custo nas empresas, ao lado de pessoal e software. A diferença é que, enquanto salários e licenças de software têm métricas claras de retorno, gastos com LLMs operam em uma zona cinzenta. "Um token só diz que o medidor rodou, não se o trabalho valeu a pena", afirmou o CEO.
O executivo deu um exemplo concreto: a maioria das organizações usa modelos de fronteira — os mais potentes e caros — para tarefas simples como resumir reuniões ou atualizar calendários. Modelos menores e mais baratos resolvem essas mesmas funções com eficiência muito superior em custo-benefício.
A conta é simples. Redirecionar apenas 10% de uma fatura de US$ 10 milhões em IA para modelos mais simples representaria uma economia de quase US$ 1 milhão. Em empresas com dezenas de milhões em gastos anuais com inference, o desperdício pode atingir centenas de milhares de dólares.
Por que isso importa para builders e devs brasileiros
No Brasil, a adoção de LLMs está acelerando. Empresas estão integrando modelos da OpenAI, Anthropic e alternativas open source em produtos e operações internas. O problema é que poucos têm visibilidade real sobre o custo por requisição, o volume de tokens processados e, principalmente, se o output justifica o investimento.
O conflito interno descrito por Glyman — financeiro querendo cortar, engenharia querendo dobrar — já acontece em startups brasileiras. Sem dados de ROI, a discussão vira batalha de opiniões, não de evidências.
Para desenvolvedores que implementam integrações com LLMs, o recado é claro: a escolha do modelo não é apenas técnica, é financeira. Usar GPT-4 para uma tarefa que um modelo de 7 bilhões de parâmetros resolve pode custar 10x mais sem ganho proporcional de qualidade.
O caminho adiante
Empresas que conseguirem instrumentar custos de IA, medir output por tarefa e escolher o modelo certo para cada caso terão vantagem competitiva significativa. O mercado está passando da fase de experimentação para a fase de otimização — e quem não fazer essa transição verá a conta explodes.