🔓Nvidia abre projeto dos servidores Rubin e revela surpresa: um chip AMD lá dentro
A Nvidia fez algo raro: abriu publicamente os diagramas e a lista completa de componentes dos seus novos servidores da linha Rubin, os mais poderosos que a empresa já produziu. E dentro dessa documentação apareceu um detalhe que chamou atenção de todo o setor: cada rack (aquele armário gigante de servidores) usa 9 pequenos processadores da AMD, sua principal concorrente em chips. --- O chip em questão é o AMD EPYC 3151, um processador simples, de uso embutido, que faz o papel de gerenciar funções internas do servidor. Não é o cérebro do sistema, mas é curioso ver a Nvidia precisando da rival para fazer seu próprio hardware funcionar. O projeto foi publicado no GitHub com licença aberta, o que significa que qualquer fabricante pode estudar e até replicar partes da arquitetura. --- É um movimento estratégico: ao abrir o projeto, a Nvidia facilita a vida de quem monta data centers e quer padronizar infraestrutura. E a presença da AMD ali dentro mostra que, por mais que as duas disputem mercado ferozmente, na prática o ecossistema de chips é mais interdependente do que parece.
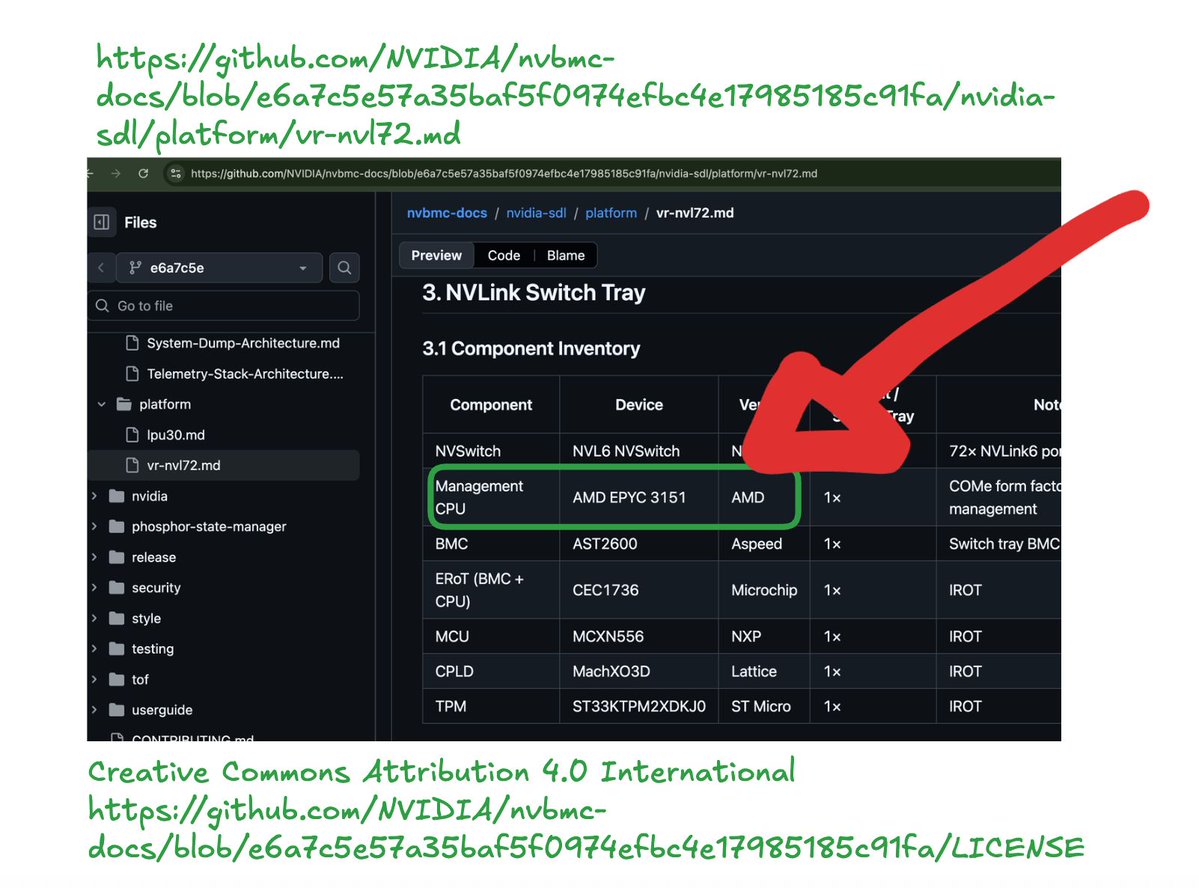
A Nvidia fez algo raro: abriu publicamente os diagramas e a lista completa de componentes dos seus novos servidores da linha Rubin, os mais poderosos que a empresa já produziu. E dentro dessa documentação apareceu um detalhe que chamou atenção de todo o setor: cada rack (aquele armário gigante de servidores) usa 9 pequenos processadores da AMD, sua principal concorrente em chips.
— @SemiAnalysis_ View on X
A Nvidia publicou no GitHub os diagramas completos de especificação de seus novos servidores Rubin, plataforma destinada a workloads de inteligência artificial de alta performance. O anúncio trouxe uma revelação curiosa: cada rack da linha utiliza nove processadores AMD EPYC 3151, modelo da principal concorrente da empresa no mercado de semicondutores.
O hardware em detalhe
Os servidores Rubin representam a próxima geração de infraestrutura da Nvidia para treinamento de grandes modelos de linguagem (LLMs) e inferência em escala. Enquanto as GPUs Rubin permanecem como núcleo computacional, os processadores AMD EPYC 3151 desempenham funções de gerenciamento interno. Trata-se de CPUs embedded de baixo consumo, responsáveis pelo controle de energia, monitoramento térmico e diagnósticos do sistema — tarefas técnicas conhecidas como Baseboard Management Controller (BMC).
A escolha da AMD não indica competição direta com as GPUs da Nvidia no processamento de IA. Os EPYC 3151 operam em nicho específico de processamento auxiliar, distante do mercado de aceleração paralela onde as empresas disputam market share. Ainda assim, a presença da rival nos racks Rubin demonstra a interdependência prática do ecossistema de semicondutores, onde até concorrentes fornecem componentes críticos uns aos outros.
Abertura estratégica e padronização
A publicação dos esquemáticos no GitHub sob licença aberta configura um movimento atípico para a Nvidia. Ao liberar a arquitetura, a empresa permite que fabricantes de hardware, cloud providers e integradores de sistemas estudem o design sem barreiras de propriedade intelectual. A padronização resultante facilita a manutenção de data centers, reduz custos de desenvolvimento e acelera a implementação de clusters de machine learning em larga escala.
Implicações para o mercado brasileiro
Para desenvolvedores e engenheiros de infraestrutura no Brasil, a documentação aberta oferece valor técnico concreto. Empresas nacionais que buscam construir data centers próprios de IA — seja para soberania digital ou redução de custos com importação — ganham acesso a referências validadas pela maior fabricante de GPUs do mundo.
Os benefícios práticos incluem: - Acesso a esquemáticos de referência para montagem de servidores customizados - Redução da curva de aprendizado em projeto de infraestrutura de alta densidade - Possibilidade de adaptar conceitos do Rubin para realidades orçamentárias locais, utilizando componentes disponíveis no mercado doméstico
A iniciativa sinaliza uma tendência de desbloqueio de especificações de hardware corporativo, tradicionalmente mantidas sob sigilo. Em um mercado onde o custo de infraestrutura de IA representa gargalo crítico para startups e centros de pesquisa, a transparência técnica permite que builders brasileiros projetem soluções mais eficientes sem depender exclusivamente de integradores internacionais.