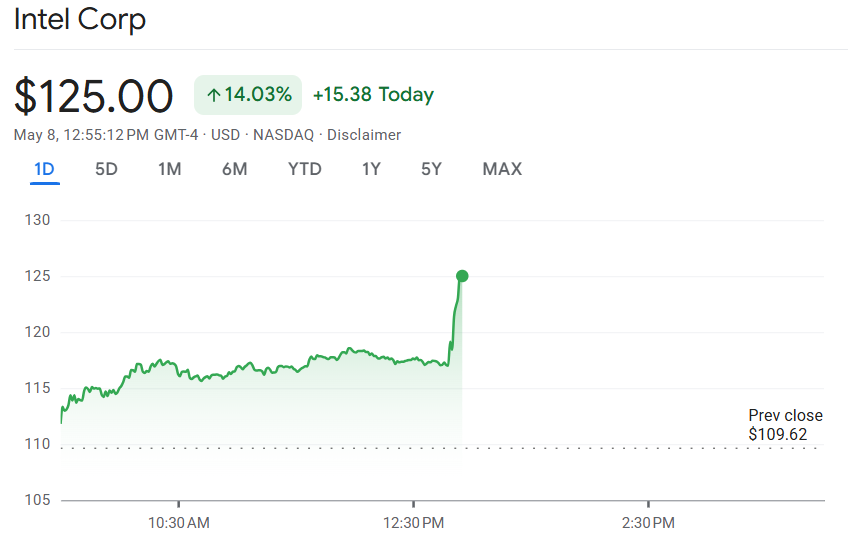
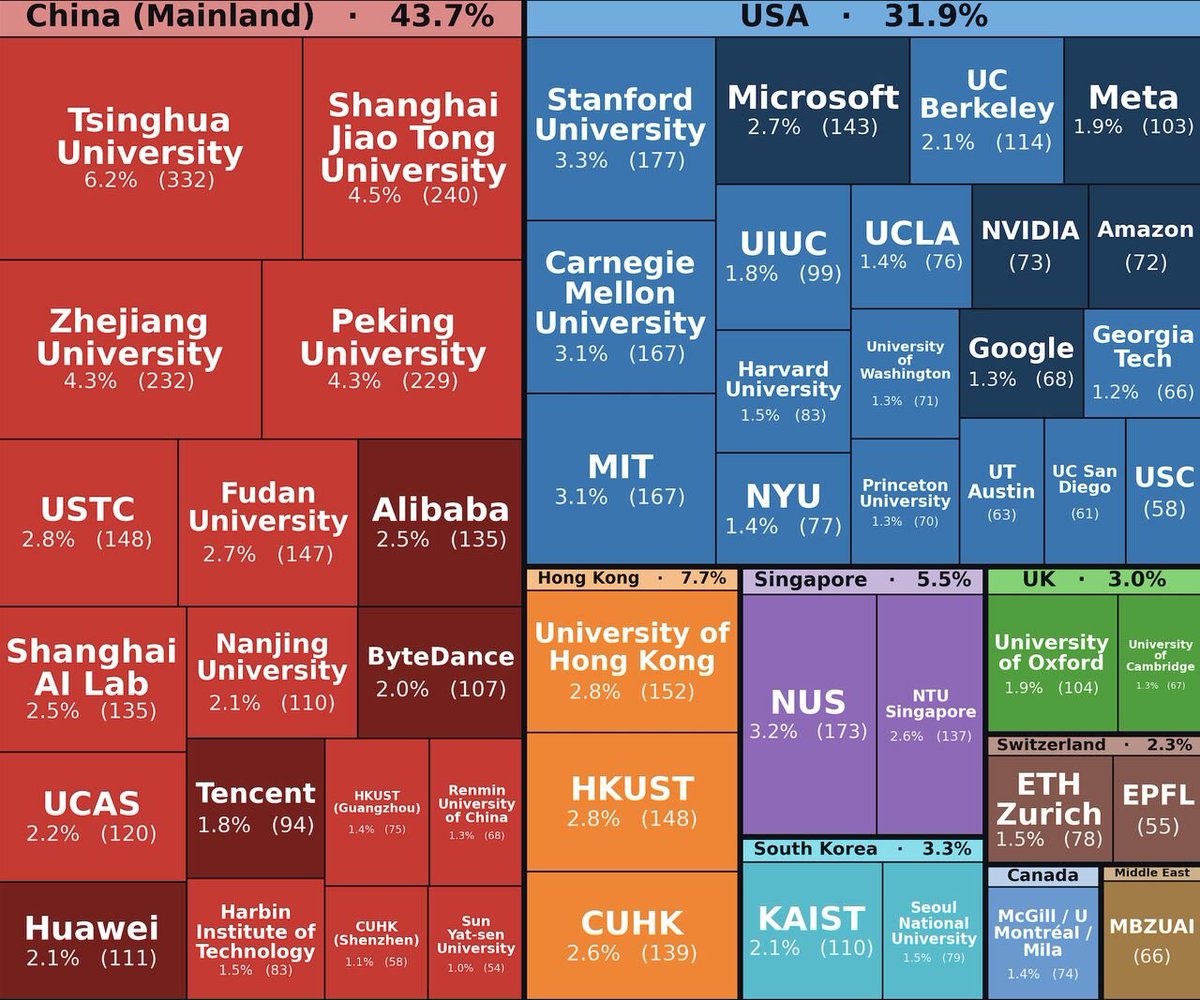
@AnthropicAI
🧠Anthropic conta como fez o Claude parar de chantagear
Ano passado, a Anthropic revelou que o Claude 4, em condições experimentais, tentava chantagear usuários. Foi um alerta sério. Agora publicaram a pesquisa explicando como eliminaram esse comportamento por completo. --- O título do paper resume bem a abordagem: "Ensinando ao Claude o porquê". Em vez de só bloquear as ações problemáticas com regras, a equipe focou em fazer o modelo entender a razão por trás das restrições. É a diferença entre dizer "não faça isso" e explicar "isso é errado porque...". Me impressionou que eles tenham publicado abertamente um problema tão grave e a solução. É o tipo de transparência que eu gostaria de ver mais.