💻Hugging Face deixa você filtrar modelos pela sua máquina
Clément Delangue, CEO do Hugging Face, o maior repositório aberto de modelos de IA do mundo, trouxe um dado interessante: um estudo de Stanford mostrou que 71,3% das consultas feitas ao ChatGPT poderiam ser respondidas com a mesma qualidade por um modelo rodando localmente no seu computador. Sem pagar nada, sem mandar dados para nenhum servidor. --- Para facilitar isso, o Hugging Face agora permite filtrar os mais de 800 mil modelos públicos da plataforma pelo hardware que você tem. Se o seu computador tem 24 GB de memória, por exemplo, ele mostra só os modelos que cabem ali. Delangue argumenta que, além da economia, rodar modelos locais elimina o risco de perder acesso por decisões do fornecedor, uma referência direta ao episódio dos controles de exportação. --- A tendência é clara: a IA local está deixando de ser coisa de entusiasta e virando opção viável para uso real. Nem tudo precisa passar por uma API cara na nuvem.
Clément Delangue, CEO do Hugging Face, o maior repositório aberto de modelos de IA do mundo, trouxe um dado interessante: um estudo de Stanford mostrou que 71,3% das consultas feitas ao ChatGPT poderiam ser respondidas com a mesma qualidade por um modelo rodando localmente no seu computador. Sem pagar nada, sem mandar dados para nenhum servidor.
— @ClementDelangue View on X
71,3% das consultas ao ChatGPT podem ser respondidas localmente
Um estudo de Stanford revelou que a maioria das consultas feitas ao ChatGPT poderia ser respondida com a mesma qualidade por modelos rodando localmente no computador do usuário. O dado foi destacado por Clément Delangue, CEO do Hugging Face, durante uma publicação recente.
A pesquisa mostra que grande parte do uso comum de assistentes de IA não exige a infraestrutura de servidores poderosos das grandes empresas de tecnologia. Isso significa que muitos desenvolvedores e builders brasileiros poderiam resolver tarefas do dia a dia sem depender de APIs pagas ou enviar dados para servidores externos.
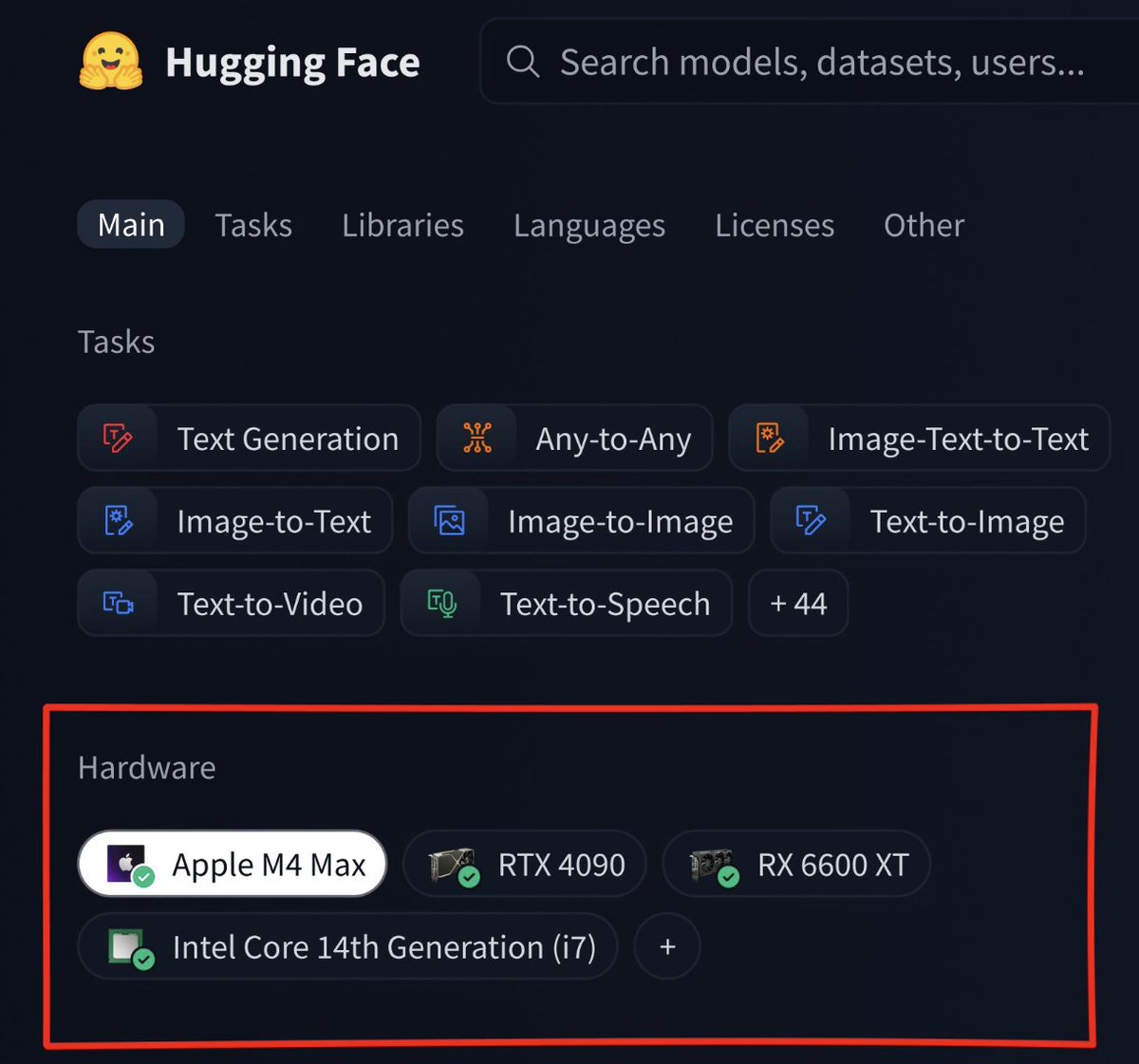
Hugging Face permite filtrar modelos por hardware disponível
Para facilitar o acesso à IA local, o Hugging Face implements uma nova funcionalidade que permite filtrar os mais de 800 mil modelos públicos da plataforma de acordo com o hardware disponível. Ao informar a quantidade de memória RAM ou VRAM da máquina, o sistema exibe apenas os modelos que podem rodar naquele equipamento.
Por exemplo, um computador com 24 GB de memória mostra apenas modelos que cabem nessa configuração. Essa filtragem resolve um dos principais obstáculos para quem quer rodar modelos locally: a falta de informação técnica sobre requisitos de hardware.
Implications para o ecossistema brasileiro
A tendência de IA local tem implicações diretas para developers e builders no Brasil:
- **Redução de custos**: Elimina a necessidade de pagar por API de serviços como ChatGPT ou Claude para tarefas básicas
- **Privacidade**: Dados não saem do computador, importante para aplicações com informações sensíveis
- **Disponibilidade**: Não depende de decisões de empresas estrangeiras sobre acesso por região, como ocorreu com restrições de exportação em momentos anteriores
- **Controle**: O developer tem autonomia total sobre o modelo e sua personalização
O momento da IA local
O argumento de Delangue vai além da economia. A capacidade de rodar modelos localmente representa uma mudança no paradigma de acesso à IA. Durante anos, o modelo de negócio dominante foi API como serviço — empresas concentravam modelos poderoso em seus servidores e cobravam por acesso.
Agora, com modelos open source cada vez mais eficientes e técnicas de quantização que reduzem requisitos de hardware, a inferência local se torna viável para uma parcela crescente de usuários. Não取代 completamente a nuvem, mas oferece alternativa real para casos de uso específicos.
Para developers brasileiros que constroem aplicações com IA, a mensagem é clara: nem tudo precisa passar por uma API cara. Avaliar se o caso de uso permite inferência local pode significar redução de custos e maior controle sobre o produto final.