📊Novo benchmark simula consultoria real e expõe o gap entre modelos
Ethan Mollick, professor da Wharton e uma das vozes mais equilibradas sobre IA, analisou os resultados do AA-Briefcase, um benchmark novo que funciona assim: em vez de perguntas de múltipla escolha, a IA precisa fazer projetos de consultoria complexos que durariam semanas para um humano. É muito mais próximo do uso real do que os testes tradicionais. --- O resultado mostra duas coisas. Primeiro, os modelos estão melhorando num ritmo impressionante, coisa de poucos meses entre saltos significativos. Segundo, e aqui está a notícia fria: a distância entre os modelos fechados (de empresas como OpenAI e Anthropic) e os modelos abertos ainda é grande nesse tipo de tarefa complexa. Melhorar em provas é uma coisa. Melhorar em trabalho real de semanas é outra bem diferente. --- Mollick também apontou uma nuance técnica no gráfico: um dos modelos listados como recente na verdade é uma versão ajustada de outro mais antigo, o que muda a leitura da velocidade de progresso. Detalhe que importa quando se tenta entender se a IA está acelerando ou apenas reciclando avanços.
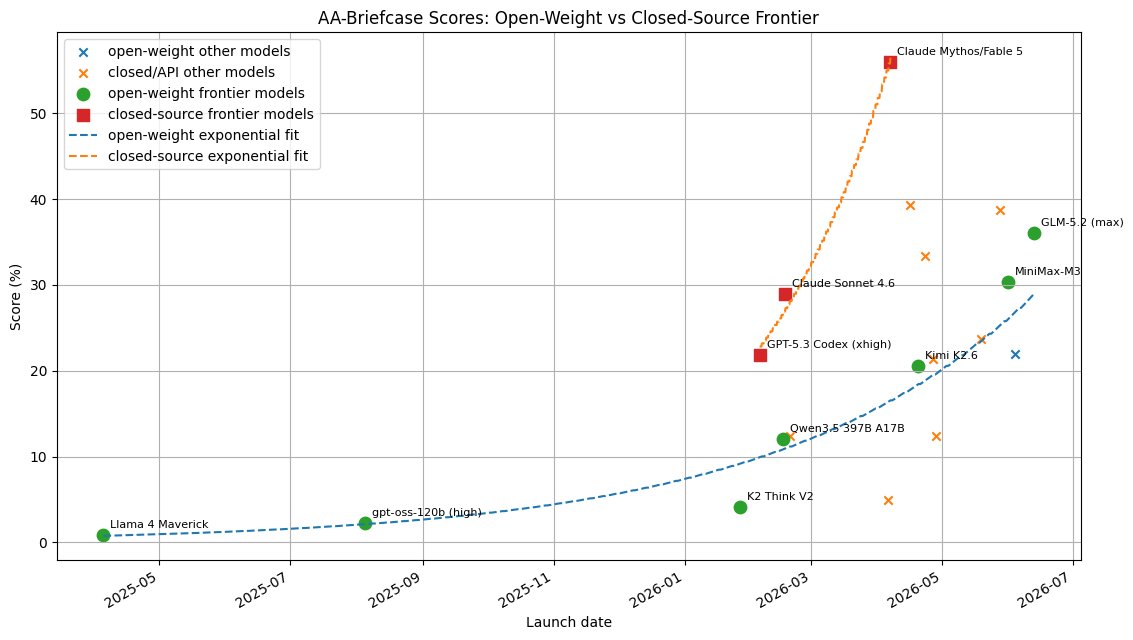
Ethan Mollick, professor da Wharton e uma das vozes mais equilibradas sobre IA, analisou os resultados do AA-Briefcase, um benchmark novo que funciona assim: em vez de perguntas de múltipla escolha, a IA precisa fazer projetos de consultoria complexos que durariam semanas para um humano. É muito mais próximo do uso real do que os testes tradicionais.
— @emollick View on X
O benchmark AA-Briefcase expõe uma realidade técnica cada vez mais relevante para quem desenvolve com inteligência artificial: modelos de linguagem fechados, como os da OpenAI e Anthropic, mantêm vantagem significativa em tarefas que replicam semanas de trabalho de consultoria, enquanto modelos abertos, embora em evolução, ainda não alcançam o mesmo patamar nesse tipo de cenário real. A avaliação foi comentada por Ethan Mollick, professor da Wharton, que alertou tanto para o ritmo de melhoria dos LLMs quanto para armadilhas na interpretação de dados de progresso.
Do teste padronizado ao projeto real
Diferente de benchmarks tradicionais com perguntas de múltipla escolha, o AA-Briefcase exige que a IA execute projetos de consultoria complexos, com duração equivalente a semanas de trabalho humano. O critério de avaliação vai além de acurácia em provas. Ele mede capacidades como: - planejamento estratégico e alocação de recursos; - análise de múltiplas variáveis em cenários dinâmicos; - entrega de soluções estruturadas e acionáveis.
Para builders e desenvolvedores brasileiros, isso representa um aviso prático: o desempenho de um LLM em rankings acadêmicos nem sempre se traduz em resultados confiáveis em pipelines de negócio de alta complexidade.
O abismo entre fechados e abertos
Os dados mostram que os principais modelos estão melhorando em ciclos curtos, às vezes de poucos meses. Contudo, o gap entre soluções proprietárias e modelos open source permanece expressivo quando o desafio é sustentar raciocínio de longo prazo e alto nível de abstração. Avançar em questionários padronizados é distinto de conduzir uma cadeia de raciocínio por múltiplas etapas, como exigem projetos reais de consultoria. Para equipes que ponderam entre hospedar um LLM local ou consumir uma API fechada, o benchmark sugere que, em tarefas de alto valor agregado, a segunda alternativa ainda oferece vantagem competitiva mensurável.
O detalhe que muda a curva
Mollick apontou uma nuance técnica que altera a leitura dos gráficos de evolução: um dos modelos listados como recente era, na verdade, uma versão ajustada — via fine-tuning ou adaptação — de uma arquitetura mais antiga. Esse detalhe desafia narrativas de aceleração contínua e exige rigor ao distinguir novas capacidades de otimizações sobre bases existentes. Para devs, essa distinção tem impacto direto na arquitetura de software: escolher uma stack de IA baseada em curvas de progresso mal interpretadas pode gerar débito técnico, retrabalho e custos de migração desnecessários.
No mercado brasileiro, onde o equilíbrio entre custo de inferência, soberania de dados e performance é decisivo, o AA-Briefcase funciona como um calibrador de expectativas. A evolução dos LLMs é real, mas ainda assim assimétrica — e quem constrói produtos precisa enxergar essa diferença antes de definir a stack.