🎙️OpenAI prepara novo modelo de voz chamado Bidi 1
Segundo o TestingCatalog, um perfil conhecido por descobrir novidades nos bastidores dos apps de IA, a OpenAI está preparando o lançamento de um modelo de voz chamado "Bidi 1" para a versão web do ChatGPT. O modelo aparecerá como uma terceira opção nas configurações, ao lado dos modos "padrão" e "avançado" que já existem. Visualmente, o botão de voz vai trocar a cor azul por amarelo. --- Os detalhes técnicos ainda são escassos, mas o nome "Bidi" sugere comunicação bidirecional, ou seja, um modo de conversa mais natural onde a IA pode falar e ouvir ao mesmo tempo, sem aquele vai e volta de turnos. Se for isso, é um passo importante para tornar a conversa por voz com IA menos parecida com uma ligação de telemarketing e mais parecida com uma conversa real.
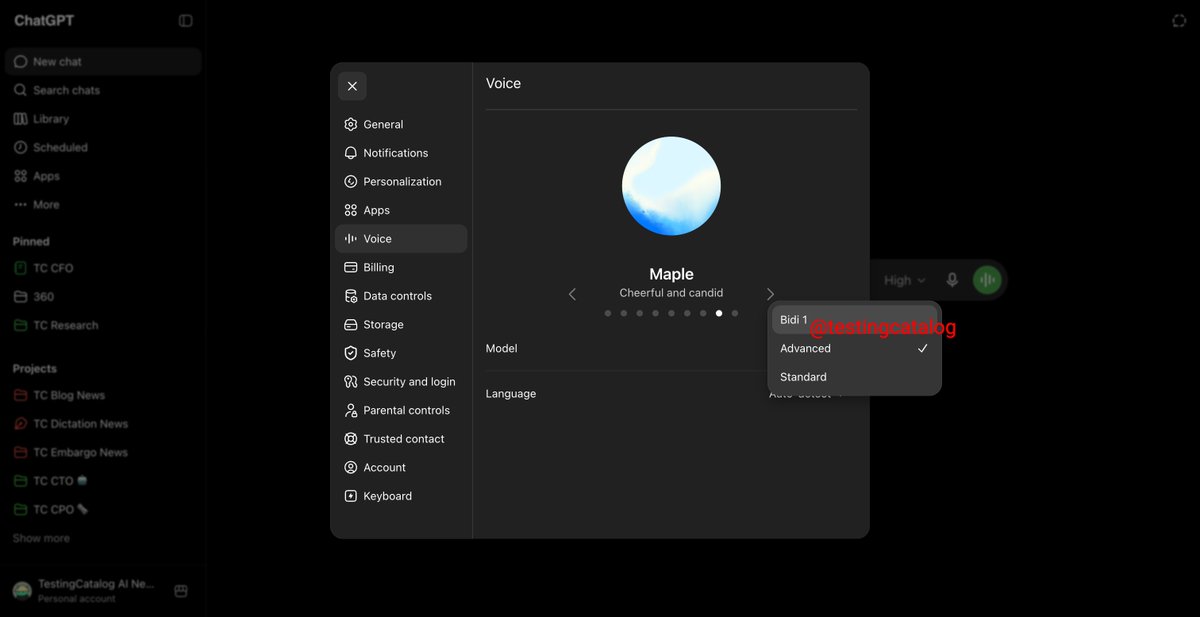
Segundo o TestingCatalog, um perfil conhecido por descobrir novidades nos bastidores dos apps de IA, a OpenAI está preparando o lançamento de um modelo de voz chamado "Bidi 1" para a versão web do ChatGPT. O modelo aparecerá como uma terceira opção nas configurações, ao lado dos modos "padrão" e "avançado" que já existem. Visualmente, o botão de voz vai trocar a cor azul por amarelo.
— @testingcatalog View on X
A OpenAI está preparando o lançamento do "Bidi 1", um novo modelo de voz projetado para a versão web do ChatGPT. A informação, revelada pelo perfil TestingCatalog — conhecido por identificar funcionalidades em desenvolvimento através de engenharia reversa — indica que a ferramenta surgirá como terceira opção nas configurações de áudio, ao lado dos modos "padrão" e "avançado". A mudança também trará uma alteração visual: o botão de microfone passará da cor azul para amarelo.
Arquitetura bidirecional e latência reduzida
O nome "Bidi" sugere implementação full-duplex, permitindo que o sistema processe fala e áudio simultaneamente. Isso elimina o padrão atual de turnos — onde usuário fala, espera, e depois a IA responde — aproximando a interação de uma conversa humana natural.
Modelos tradicionais de speech-to-text e text-to-speech operam em pipeline sequencial, gerando latência perceptível entre interações. Sistemas bidirecionais implementam streaming contínuo de áudio, com processamento em tempo real que detecta pausas naturais e interrupções, redu