🚇Modelo de IA minúsculo supera gigantes ao ser treinado só para o metrô de Paris
Um modelo de IA com apenas 600 milhões de parâmetros (a medida de complexidade de um modelo) superou modelos com 397 bilhões de parâmetros e até o Claude Sonnet 4.5 da Anthropic em uma tarefa específica: operar o metrô de Paris. O projeto foi desenvolvido pela SYNTH, que treinou o modelo exclusivamente com dados da infraestrutura de transporte parisiense. --- A lição é simples e poderosa: nem sempre você precisa do modelo mais caro e mais inteligente do mercado. Quando o problema é bem definido e os dados são bons, um modelo especializado e muito menor pode ser mais preciso, mais barato e mais rápido. É como contratar um eletricista experiente em vez de chamar um engenheiro generalista para trocar uma tomada. Ahmad Osman, pesquisador de IA, resumiu: 'O futuro pertence a quem faz as apostas certas'.
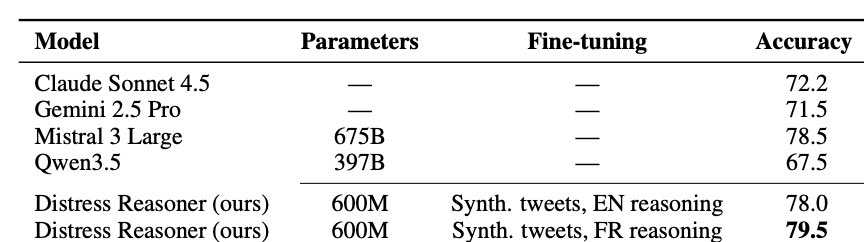
Um modelo de IA com apenas 600 milhões de parâmetros (a medida de complexidade de um modelo) superou modelos com 397 bilhões de parâmetros e até o Claude Sonnet 4.5 da Anthropic em uma tarefa específica: operar o metrô de Paris. O projeto foi desenvolvido pela SYNTH, que treinou o modelo exclusivamente com dados da infraestrutura de transporte parisiense.
— @TheAhmadOsman View on X
Um modelo de inteligência artificial com apenas 600 milhões de parâmetros superou sistemas com 397 bilhões de parâmetros e o Claude Sonnet 4.5 da Anthropic em uma tarefa operacional altamente específica: gerenciar a infraestrutura do metrô de Paris. O projeto, desenvolvido pela SYNTH, desafia a lógica de que maior sempre significa melhor no universo dos LLMs. Ao treinar o modelo exclusivamente com dados do transporte parisiense, a empresa mostrou que a especialização domain-specific pode entregar resultados mais robustos que a escala bruta, desde que o problema esteja bem delimitado.
Especialização vence escala em cenários operacionais
A SYNTH criou um sistema otimizado para uma única vertical. Grandes LLMs generalistas são projetados para performar em milhares de tarefas distintas, o que exige recursos computacionais massivos e inevitavelmente aumenta a latência durante a inferência. No caso do metrô de Paris, o modelo menor apresentou performance superior porque não desperdiçava capacidade de processamento em conhecimento irrelevante ao contexto de transporte público. A arquitetura enxuta permitiu respostas mais rápidas e precisas em um ambiente onde erros operacionais têm custo alto e a eficiência é prioridade.
Para builders e desenvolvedores brasileiros, o caso funciona como um manual prático de arquitetura de IA. A indústria frequentemente associa qualidade ao número de parâmetros, mas o custo de rodar modelos massivos em produção pode inviabilizar projetos, especialmente em startups, scale-ups e aplicações de nicho com margens apertadas.
O que muda na prática para devs brasileiros
A lição se aplica diretamente ao ecossistema local:
- **Fine-tuning em bases proprietárias**: empresas de logística, agronegócio e fintechs brasileiras podem extrair mais valor de modelos enxutos treinados sobre dados internos do que de APIs generalistas de grande porte;
- **Custo de inferência controlado**: modelos menores consomem menos GPU e energia, fatores decisivos em um mercado com dólar alto e infraestrutura cloud cara;
- **Latência reduzida**: em aplicações em tempo real, como gestão de tráfego urbano ou controle de estoque, a velocidade de resposta frequentemente pesa mais que a amplitude enciclopédica do modelo;
- **Deployment simplificado**: modelos compactos são mais fáceis de hospedar on-premise ou em edge computing, alternativas relevantes para empresas com restrições de compliance e soberania de dados.
O pesquisador de IA Ahmad Osman resumiu a tendência: o diferencial não está no tamanho do modelo, mas na precisão da aposta. Em um mercado onde orçamentos de tecnologia são enxutos, a capacidade de delimitar problemas claros e alimentar modelos especializados com dados de qualidade torna-se vantagem competitiva mensurável.