⚖️Mapa mostra quem está processando quem no mundo da IA
Luiza Jarovsky, especialista em privacidade e IA, compartilhou um mapa visual criado pelo pesquisador Matt Candelish que mostra o emaranhado de processos judiciais no setor de inteligência artificial. A visualização revela uma rede densa de ações envolvendo grandes empresas de tecnologia, editoras, artistas, gravadoras e agências de notícias. --- O cenário reforça que a briga pelo direito autoral na era da IA generativa está longe de terminar. Empresas como OpenAI, Stability AI, Meta e Google aparecem como alvos recorrentes, enquanto grupos de artistas, escritores e veículos de mídia tentam definir nos tribunais o que é uso justo de dados para treinar modelos. Ainda não há consenso legal, e o resultado desses casos vai definir as regras do jogo para a próxima década.
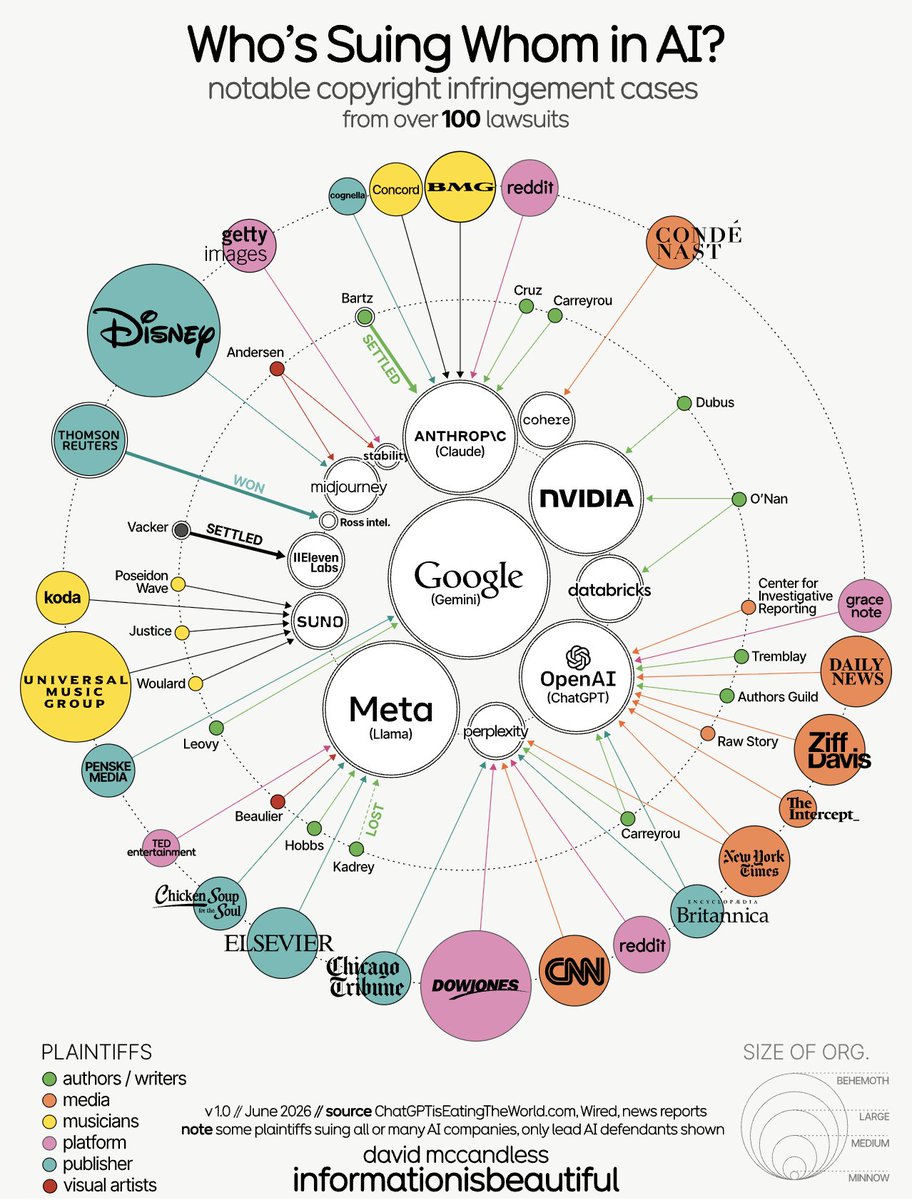
Luiza Jarovsky, especialista em privacidade e IA, compartilhou um mapa visual criado pelo pesquisador Matt Candelish que mostra o emaranhado de processos judiciais no setor de inteligência artificial. A visualização revela uma rede densa de ações envolvendo grandes empresas de tecnologia, editoras, artistas, gravadoras e agências de notícias.
— @LuizaJarovsky View on X
O setor de inteligência artificial vive um momento de alta tensão jurídica. Um mapa visual compilado pelo pesquisador Matt Candelish e divulgado pela especialista em privacidade Luiza Jarovsky revela uma rede complexa de processos judiciais que envolve gigantes da tecnologia, editoras, artistas, gravadoras e agências de notícias. A visualização deixa claro que a indefinição sobre direitos autorais no treinamento de large language models e sistemas de difusão já deixou de ser uma discussão acadêmica e se transformou em uma disputa judicial com proporções globais.
O emaranhado de demandas
A imagem consolidada por Candelish mostra empresas como OpenAI, Stability AI, Meta e Google no centro de dezenas de ações. De um lado, desenvolvedoras de modelos generativos argumentam que a raspagem de dados públicos se enquadra em exceções de direito autoral, como o fair use. Do outro, criadores de conteúdo e veículos de mídia contestam a apropriação de obras sem autorização ou compensação. O resultado é um cenário sem precedentes: nenhuma jurisdição estabeleceu ainda um consenso sólido sobre se a coleta massiva de dados para treinamento de IA constitui infração ou prática legítima.
Impacto direto para o ecossistema brasileiro
Para builders e desenvolvedores no Brasil, o efeito prático é imediato. O país conta com a LGPD e o Marco Civil da Internet, que estabelecem regras claras sobre uso de conteúdo e responsabilidade. Embora a maioria dos processos mapeados ocorra nos Estados Unidos e na Europa, as decisões desses tribunais tendem a influenciar globalmente o licenciamento de datasets e as exigências de compliance para startups brasileiras.
Quem trabalha com fine-tuning, RAG ou construção de bases de treinamento precisa prestar atenção em três frentes:
- **Rastreabilidade dos dados**: documentar a origem dos datasets torna-se obrigação, não apenas boa prática.
- **Licenciamento**: a distinção entre dados públicos e dados livres para uso comercial está se estreitando rapidamente.
- **Transparência de modelos**: publicar cards de dados e informações sobre treinamento pode reduzir exposição legal e facilitar due diligence.
O que esperar nos próximos meses
Sem um acordo global ou marco regulatório unificado, os tribunais continuarão a definir os limites do uso de dados na era dos modelos generativos. O resultado desses processos não interessa apenas aos departamentos jurídicos. Vai determinar se startups e desenvolvedores independentes mantêm acesso a datasets acessíveis ou se enfrentarão barreiras de entrada sustentadas por custos crescentes de licenciamento.
A litigiosidade do setor sinaliza que a fase de terra de ninguém na coleta de dados para IA está chegando ao fim. Para quem está construindo produtos no Brasil, acompanhar essas decisões deixou de ser opcional.