📄Baidu lança leitor de texto por IA que roda até em celular
A Baidu, gigante de tecnologia chinesa, lançou o PP-OCRv6, um modelo de OCR (reconhecimento óptico de caracteres, a tecnologia que lê textos em imagens) que chama atenção pelo tamanho: a versão menor tem apenas 1,5 milhão de parâmetros. Para comparação, o ChatGPT tem centenas de bilhões. Isso significa que ele roda em dispositivos simples, como celulares e equipamentos industriais, sem precisar de conexão com a nuvem. --- O modelo suporta mais de 48 idiomas e reconhece desde texto impresso e escrito à mão até informações em telas de computador e cartões. É o tipo de ferramenta que não gera manchetes glamorosas, mas resolve problemas reais: digitalizar documentos, ler placas, extrair dados de formulários. E o fato de rodar localmente, sem mandar seus dados para servidores distantes, é um ponto importante para privacidade.
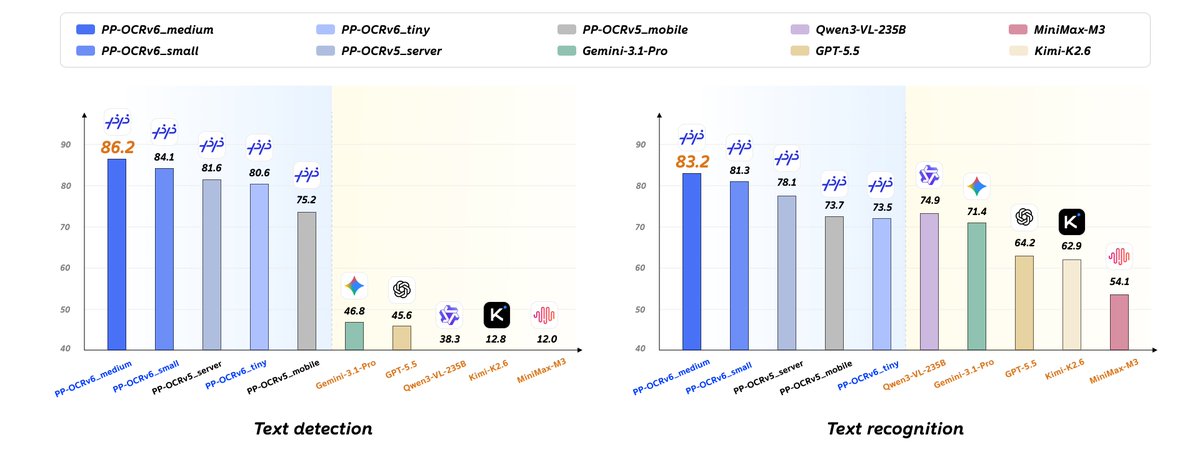
A Baidu, gigante de tecnologia chinesa, lançou o PP-OCRv6, um modelo de OCR (reconhecimento óptico de caracteres, a tecnologia que lê textos em imagens) que chama atenção pelo tamanho: a versão menor tem apenas 1,5 milhão de parâmetros. Para comparação, o ChatGPT tem centenas de bilhões. Isso significa que ele roda em dispositivos simples, como celulares e equipamentos industriais, sem precisar de conexão com a nuvem.
— @AdinaYakup View on X
O que torna o PP-OCRv6 diferente
A Baidu lançou o PP-OCRv6, um modelo de reconhecimento óptico de caracteres (OCR) com apenas 1,5 milhão de parâmetros na versão mais leve. Para efeito de comparação, o ChatGPT possui centenas de bilhões de parâmetros. Essa diferença de escala permite que o modelo execute diretamente em dispositivos com recursos limitados, como smartphones Android de entrada, equipamentos industriais antigos e sistemas embarcados, sem depender de conexão com a nuvem.
Como a redução de parâmetros impacta o uso prático
O tamanho reduzido não é apenas uma curiosidade técnica. Ele permite que desenvolvedores implementem OCR em cenários onde anteriormente seria inviável:
- Aplicativos móveis que processam documentos offline
- Sistemas de leitura de placas em estacionamentos e portarias
- Digitalização de formulários em áreas com conectividade instável
- Equipamentos industriais que precisam ler etiquetas em tempo real
A versão leve do modelo consome poucos recursos de memória e processamento, tornando-o adequado para dispositivos com chips de entrada.
Funcionalidades e suporte multilíngue
O PP-OCRv6 reconhece mais de 48 idiomas, incluindo português brasileiro. Ele processa texto impresso, manuscrito, informações em telas de computador e dados de cartões de identificação. Essa versatility permite aplicações diversas: desde a digitalização de documentos fiscais até a extração automática de informações de contratos.
Privacidade como diferencial
Por rodar localmente, o modelo não envia imagens para servidores externos. Isso resolve uma preocupação recorrente em aplicações que lidam com documentos sensíveis: dados pessoais, informações financeiras e registros médicos podem ser processados sem sair do dispositivo do usuário. Para o mercado brasileiro, onde a LGPD impõe restrições rigorosas sobre transferência de dados pessoais, essa característica representa uma vantagem concreta.
O que isso significa para desenvolvedores brasileiros
Para builders que trabalham com automação de processos, aplicativos de produtividade ou sistemas de gestão, o PP-OCRv6 oferece uma alternativa viável a APIs de OCR baseadas em nuvem. O custo de processamento cai significativamente, já que não há chamadas a serviços externos. A latência também diminui, já que o resultado retorna instantaneamente.
É uma ferramenta que não gera manchetes protagonizadas por modelos generativos, mas resolve problemas reais de engenharia: digitalização de documentos, leitura de códigos de barras, extração de dados de formulários. Para quem constrói soluções em edge computing, o lançamento da Baidu adiciona uma opção ao repertório de modelos leves disponíveis.