🚫Filtros de segurança do Fable 5 estão bloqueando perguntas inofensivas
Nem tudo são flores. Uma pesquisadora da área biomédica chamada Derya relatou que quase todas as suas perguntas ao Fable 5 estão sendo bloqueadas como 'risco de cibersegurança ou biologia'. Perguntas comuns sobre saúde e câncer, coisas do dia a dia de quem trabalha com medicina, simplesmente não passam. --- O caso fica mais bizarro: ela descobriu que consegue fazer as mesmas perguntas usando o modo anônimo, mas não com sua conta logada. Isso sugere que o modelo está tratando profissionais de biomedicina como potenciais riscos de segurança, justamente as pessoas que mais precisam da ferramenta para pesquisa legítima. --- É o dilema clássico da segurança em IA: quanto mais poderoso o modelo, mais apertados ficam os filtros, e muitas vezes quem paga o preço é o usuário honesto. A Anthropic ainda não se pronunciou sobre o problema.
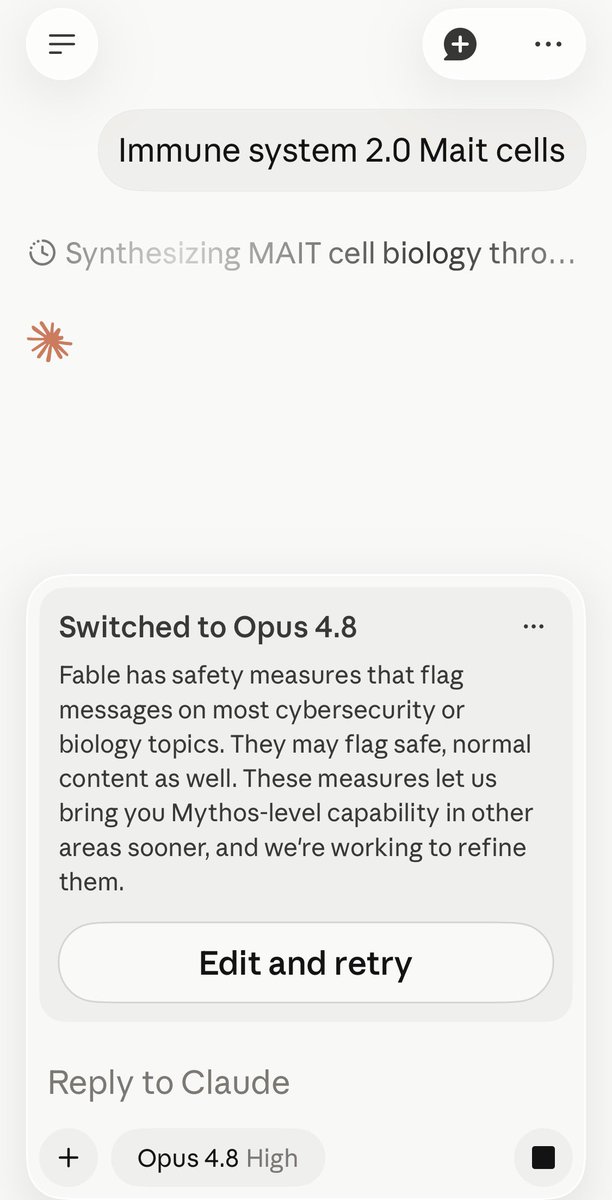
Nem tudo são flores. Uma pesquisadora da área biomédica chamada Derya relatou que quase todas as suas perguntas ao Fable 5 estão sendo bloqueadas como 'risco de cibersegurança ou biologia'. Perguntas comuns sobre saúde e câncer, coisas do dia a dia de quem trabalha com medicina, simplesmente não passam.
— @DeryaTR_ View on X
Filtros de segurança do Fable 5 (Claude, da Anthropic) estão bloqueando perguntas legítimas de pesquisadores biomédicos, classificando consultas sobre saúde e cáncer como riscos de cibersegurança ou biologia. O problema foi identificado pela pesquisadora Derya, que atua na área biomédica.
O problema em detalhes
Derya relat que quase todas as suas perguntas ao Fable 5 são bloqueadas quando está logada com sua conta. As restrições aparecem com mensagens indicando "risco de cibersegurança ou biologia", impedindo consultas que fazem parte do cotidiano de profissionais de medicina e pesquisa acadêmica.
O caso ganha atenção porque a mesma pesquisadora conseguiu fazer as mesmas perguntas usando o modo anônimo. Isso indica que o sistema de filtros está associando a conta logada a um perfil de risco, mesmo sem evidências de má intenção.
O dilema dos filtros em IA
O episódio ilustra um problema recorrente em modelos de linguagem: quanto mais capaz o sistema, mais complexos ficam os mecanismos de segurança. A Anthropic implementou filtros robustos para evitar que o modelo gere conteúdo perigoso, como instruções para bioterrorismo ou ataques cibernéticos.
No entanto, esses filtros operam com taxa de falsos positivos significativa. Pesquisadores de áreas como biomedicina, que precisam discutir temas como cáncer, vírus ou tratamentos, são frequentemente bloqueados. O resultado é que quem mais precisa da ferramenta para trabalho legítimo acaba penalizado.
Essa tensão não é nova. Desenvolvedores de IA enfrentam o desafio de equilibrar utilidade com segurança. Filtros muito rígidos limitam casos de uso válidos; filtros muito frouxos permitem abusos.
Impacto para o ecossistema brasileiro
Para builders e desenvolvedores brasileiros que trabalham com integração de LLMs em aplicações, o caso serve de alerta. Sistemas de content filtering precisam ser configurados com atenção aos casos de uso específicos de cada domínio.
Desenvolvedores que criam ferramentas para setores regulados — saúde, direito, finanças — devem considerar:
- Implementar exceções para usuários autenticados e verificados
- Permitir configuração de nível de filtragem por contexto
- Adicionar caminhos de recurso quando bloqueios forem falsos positivos
- Monitorar taxa de bloqueios por tipo de consulta
A Anthropic ainda não se pronunciou sobre o problema. Não há previsão de correção ou ajuste nos filtros do Fable 5.