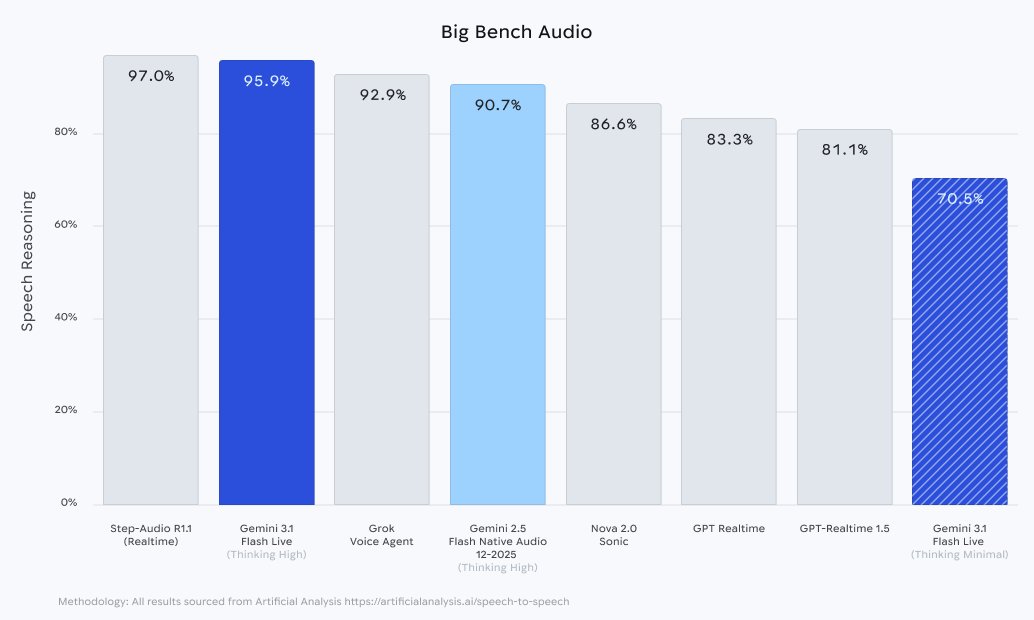
🗣️Gemini virou voz e visão em tempo real
O Google empurrou o Gemini 3.1 Flash Live como seu modelo para agentes que precisam ouvir, falar e enxergar sem aquela latência constrangedora que faz toda demo parecer atendimento de operadora. A promessa é conversa mais natural, menos pausa esquisita e resposta mais confiável para fluxos multimodais. --- Na prática, isso puxa a disputa de IA para a camada de interface. O modelo que dominar voz em tempo real não ganha só benchmark - ganha o lugar de assistente padrão dentro de apps, navegadores, carros, suporte e tudo que hoje ainda depende de clique. É uma guerra menos de chat e mais de presença.

Introducing Gemini 3.1 Flash Live, our new realtime model to build voice and vision agents!! We have spent more than a year improving the model + infra + experience, the results? A step function improvement in quality, reliability, and latency. https://t.co/0esYpmDy5l
— @OfficialLoganK View on X
O Google lançou o Gemini 3.1 Flash Live, modelo de IA multimodal projetado especificamente para eliminar a latência que até agora inviabilizava agentes de voz e visão em tempo real. A novidade representa mais de um ano de otimizações conjuntas entre arquitetura do modelo, infraestrutura de inferência e camada de experiência do usuário, prometendo respostas significativamente mais rápidas e confiáveis para fluxos que combinam áudio, imagem e texto simultaneamente.
O fim da "pausa constrangedora"
A principal barreira técnica para assistentes virtuais realmente naturais nunca foi apenas a qualidade da geração de linguagem, mas o tempo de resposta. Modelos tradicionais apresentam delays que transformam interações em diálogos truncados, similares a atendimentos automatizados de operadoras. O Gemini 3.1 Flash Live ataca diretamente esse gargalo com otimizações de baixo nível que reduzem a latência percebida, permitindo conversas contínuas onde o sistema processa entrada de voz e visual enquanto o usuário ainda fala.
Essa melhoria não é incremental. A