🤯IA chinesa se auto-treinou sem supervisão humana
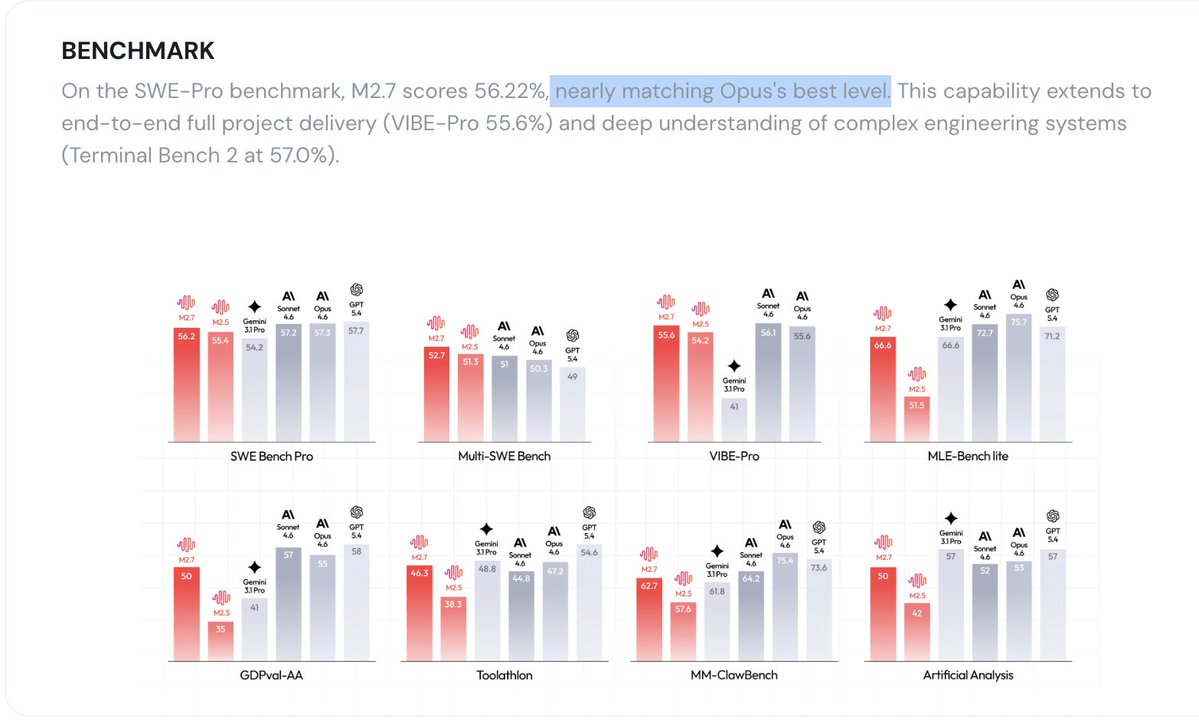
A MiniMax, empresa chinesa que você provavelmente nunca ouviu falar, acaba de fazer algo que ninguém esperava: criou um modelo de IA que literalmente se treinou sozinho. O M2.7 passou por mais de 100 rodadas de auto-aperfeiçoamento, sem intervenção humana, e melhorou 30%. --- Pra colocar em perspectiva: esse modelo agora compete com o Claude Opus 4.6 e o GPT-5.4 em benchmarks de código. E roda em uma única GPU A30 - hardware que você encontra em qualquer datacenter decente. A China não só alcançou os americanos, ela chegou por um caminho diferente. --- O mais impressionante? O M2.7 já faz 30 a 50% da pesquisa de IA da própria MiniMax. Sim, a IA está ajudando a criar a próxima versão de si mesma. Se isso não te dá um frio na espinha, talvez devesse.
fuck me china just launched the 1st AI model that autonomously built itself... and its as good as claude opus 4.6 and gpt-5.4 - minimax M2.7 trained itself through 100+ rounds of autonomous self-improvement. 30% gain. No humans involved - what the actual f*ck - model now handles 30-50% of the AI lab's OWN AI research - beats gemini 3.1 at coding and pretty much matches opus 4.6 + gpt 5.4 😶 (china used to lag now they match - doesn't require crazy hardware to run (single a30 gpu) - absolutely CRUSHES tasks: financial modelling, coding, openclaw - one-shotted the chinese have officially caught up. self-improving ai is a real thing. all researchers did was set an objective and the model figured the rest out. i wasn't expecting this from minimax. im now wondering wtf deepseek is going to be like.
— @cryptopunk7213 View on X
O modelo que se treinou sozinho
A MiniMax, empresa chinesa de IA, lançou o primeiro modelo de linguagem que alcançou desempenho equivalente ao Claude Opus 4.6 e GPT-5.4 através de 100 rodadas de auto-aperfeiçoamento — sem qualquer intervenção humana no processo de training. O M2.7 melhorou 30% em benchmarks de código e agora executa 30% a 50% da pesquisa de IA da própria empresa.
Essa não é uma evolução incremental. É uma mudança de paradigma.
O que mudou
Modelos de linguagem tradicionalmente dependem de datasets rotulados por humanos para fine-tuning. O processo envolve equipes de anotadores, revisão manual e múltiplos ciclos de ajuste. A MiniMax eliminou essa etapa: bastou definir um objetivo e o modelo encontrou o caminho sozinho.
O resultado rodou em uma única GPU A30 — hardware presente em datacenters comerciais, sem necessidade de clusters massivos. Em testes de financial modelling, coding e openclaw, o M2.7 superou o Gemini 3.1 e empatou com os melhores modelos ocidentais.
Por que isso importa para builders brasileiros
O auto-treinamento reduz drasticamente o custo de迭代ção de modelos. Para startups e times de desenvolvimento no Brasil, onde recursos de compute são limitados, a possibilidade de rodar um modelo competitivo em hardware acessível muda a equação econômica.
Além disso, a IA agora ajuda a criar a próxima versão de si mesma. O M2.7 já participa ativamente da pesquisa que gera seus sucessores. Esse ciclo auto-referencial — a máquina melhorando a si mesma — é o que pesquisadores chamam de recursive self-improvement e representa um marco técnico real, não especulação.
O contexto da corrida global
A China tradicionalmente lagava atrás dos EUA em modelos de fronteira. O M2.7 indica que Pequim encontrou uma rota alternativa: em vez de competir em escala de compute, competem em eficiência de training. A MiniMax demonstrou que auto-supervised learning em escala pode produzir resultados comparáveis aos melhores modelos ocidentais.
A próxima pergunta é o que o DeepSeek — outra empresa chinesa — vai apresentar. Se a MiniMax já chegou a esse nível sem alarde, o que ainda está por vir?

