⚡GPT-5.4 mini e nano: menores, mais rápidos, mais baratos
A OpenAI lançou o GPT-5.4 mini e nano - os modelos compactos mais capazes da empresa até agora. O mini é duas vezes mais rápido que a versão anterior, otimizado pra programação, controle de computador e trabalho com imagens e vídeos. --- O nano é o modelo mais barato e leve da família, pensado pra tarefas simples do dia a dia. Uma curiosidade interessante: chips antigos estão ficando mais caros pra alugar, porque modelos menores e melhores conseguem extrair mais valor do mesmo hardware.
GPT-5.4 mini is available today in ChatGPT, Codex, and the API. Optimized for coding, computer use, multimodal understanding, and subagents. And it’s 2x faster than GPT-5 mini. https://t.co/DKh2cC5S3F https://t.co/sirArgn37L
— @OpenAI View on X
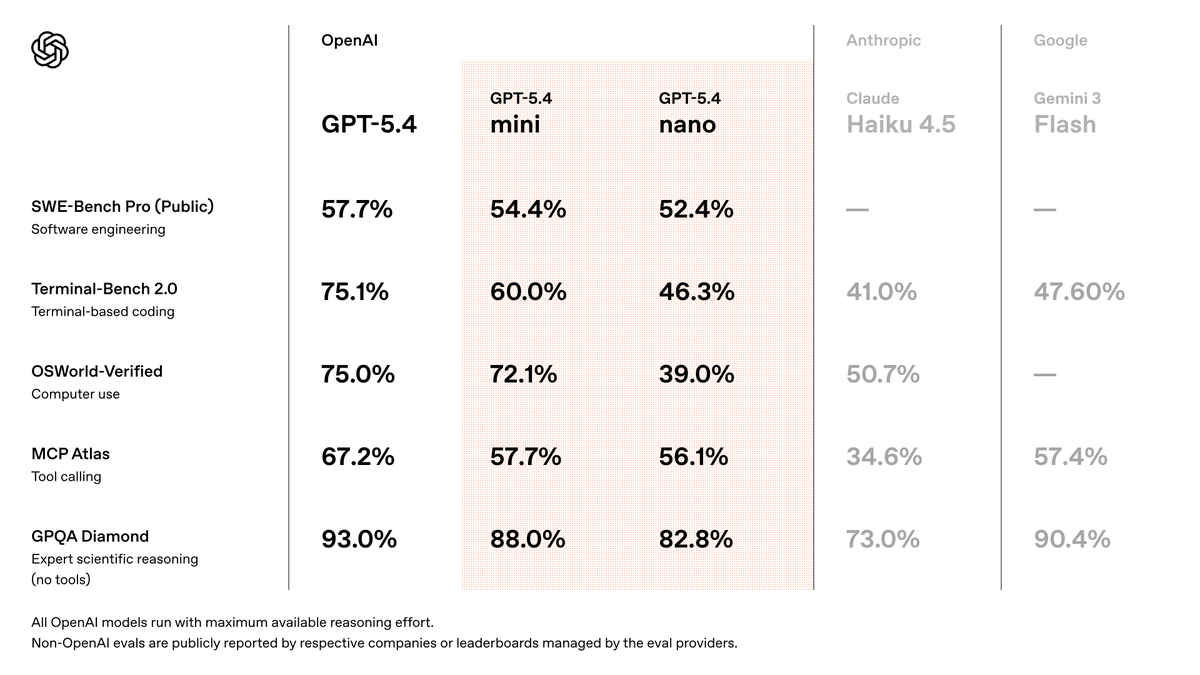
A OpenAI disponibilizou nesta semana dois novos modelos compactos: o GPT-5.4 mini e o GPT-5.4 nano. Ambos já estão acessíveis via ChatGPT, Codex e API, marcando uma atualização significativa na família de modelos menores da empresa. A novidade principal está no equilíbrio entre capacidade computacional e eficiência de custo, com implicações diretas para arquiteturas de software e gestão de infraestrutura.
GPT-5.4 mini: velocidade duplicada para tarefas complexas
O GPT-5.4 mini representa um salto na performance relativa. Segundo a OpenAI, o modelo opera com o dobro da velocidade de seu antecessor, o GPT-5 mini, mantendo ou expandindo as capacidades em áreas críticas para desenvolvedores: programação, controle de interface (computer use), processamento multimodal e orquestração de subagentes.
Para equipes técnicas, isso significa redução de latência em pipelines de agentes autônomos e menor custo por operação em workflows que demandam múltiplas chamadas de API. A otimização para coding e computer use posiciona o modelo como alternativa viável para automação de interfaces gráficas e geração de código em tempo real, sem o overhead de modelos maiores como o GPT-5 ou GPT-5 Pro.
GPT-5.4 nano: otimização para edge e tarefas rotineiras
O GPT-5.4 nano é a aposta da OpenAI para processamento leve. Projetado para tarefas simples do dia a dia, o modelo oferece o ponto de entrada mais barato da família GPT-5.4. Sua aplicação ideal envolve classificação de texto, respostas rápidas a queries simples e filtragem inicial de dados — cenários onde a latência baixa e o custo mínimo superam a necessidade de raciocínio profundo.
Para startups e desenvolvedores brasileiros, o nano possibilita escalar operações de IA generativa sem explosão nos custos de inferência, especialmente em aplicações com alto volume de requisições e baixa complexidade individual.
O paradoxo do hardware legado
Uma consequência secundária, mas relevante para engenheiros de infraestrutura, está no mercado de hardware. Modelos menores e mais eficientes estão aumentando a demanda por chips antigos — sim, hardware legado está ficando mais caro para alugar. A lógica é simples: se um modelo compacto consegue extrair valor produtivo de GPUs ou TPUs de gerações anteriores, o custo de oportunidade de não usar esse hardware aumenta. Datacenters estão reprecificando máquinas que, há meses, seriam consideradas obsoletas para cargas de trabalho de IA.
Implicações para o ecossistema brasileiro
Para desenvolvedores e builders no Brasil, onde custos de cloud e latência internacional são variáveis críticas, a combinação de mini e nano oferece granularidade na arquitetura. É possível rotear tarefas simples para o nano, manter o mini para processamento intermediário e reservar modelos maiores apenas para edge cases complexos. Essa estratificação permite otimizar orçamentos de inferência sem sacrificar a experiência do usuário final.